From Metrics to Meaning: A Hybrid Framework for Monitoring AI in Global Health

Image created with ChatGPT4o
In our last blog, we argued that too many digital health tools are still hiding behind impressive-sounding topline metrics—users “engaged” because they clicked once, tools “scaled” because they’re technically live, or AI “trusted” without clarity on what trust means or how it’s measured.
At Audere, we believe that if AI is going to be used in life-or-death contexts, especially among underserved populations, we can’t afford illusions. We need to measure what matters—with precision, humility, and honesty.
This post unpacks how we’re doing just that through a Hybrid M&E framework—one we first developed to evaluate computer vision (CV) tools for diagnostics and have since adapted and expanded for real-time, real-world LLM-powered interventions.
Why a Hybrid Approach?
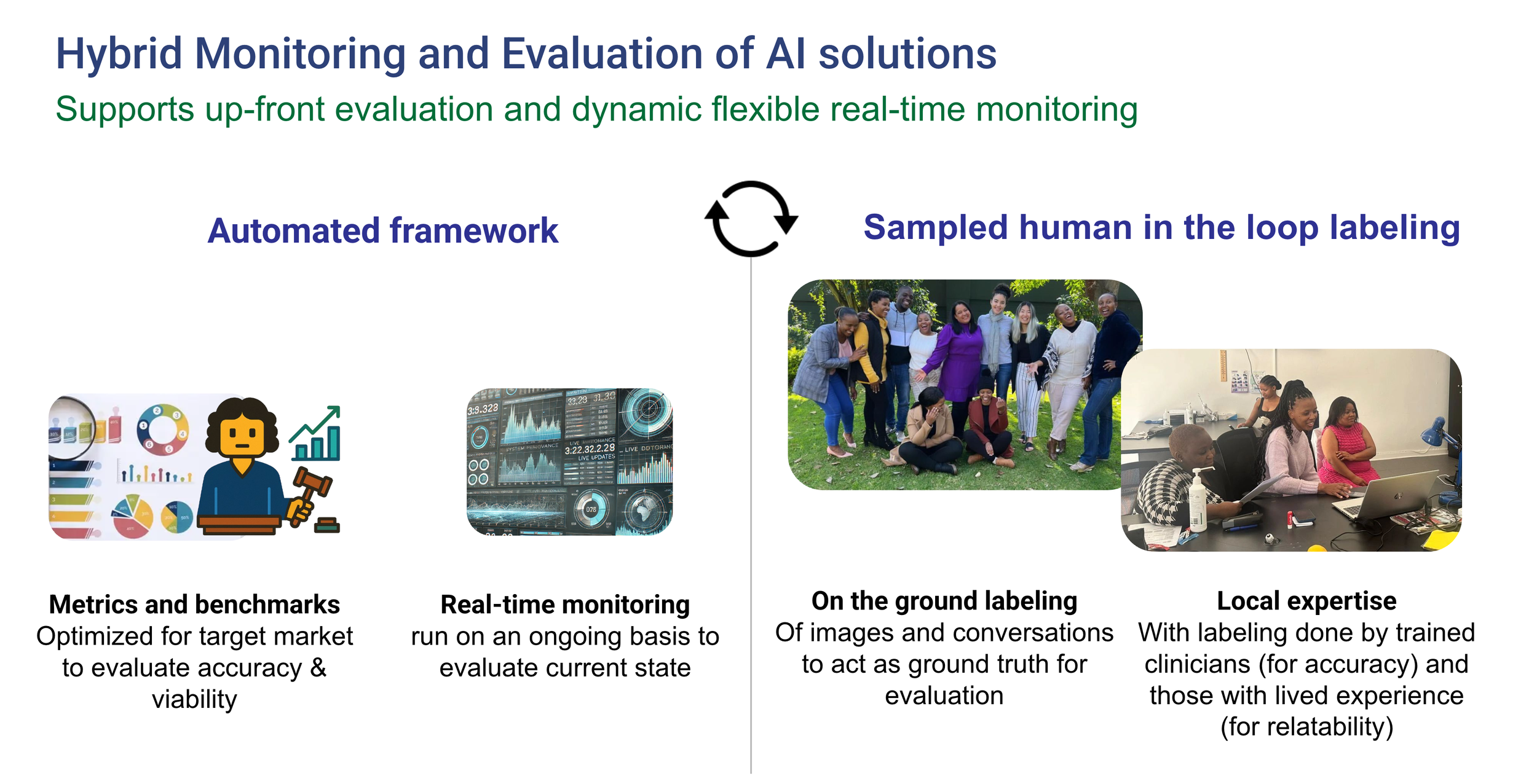
Audere’s hybrid approach to monitoring and evaluation of AI solutions
Monitoring and evaluating AI for global health isn’t a “nice-to-have”—it’s a necessity. But it’s also uniquely difficult. AI models, especially LLMs, are not static software products. Their outputs vary based on input phrasing, model version, and real-world context. Errors can be subtle, systemic, or sporadic—and when left unchecked, dangerous.
This is why we take a hybrid approach:
Automated evaluation lets us scale that learning—cost-effectively and consistently.
Manual (human-in-the-loop) evaluation gives us high-fidelity feedback rooted in local expertise and lived experience.
Together, they create a feedback loop that’s rigorous, rapid, and adaptable.
Building on CV: What We Learned

Computer Vision automated “report card” snippet example for an RDT
Our work on malaria diagnostics using computer vision helped shape this approach. Early on, we realized success couldn’t be measured by deployment numbers alone. We needed to ask:
How accurate was our CV at reading rapid diagnostics (RDT) while maintaining a tiny footprint (essential for our use cases)?
Did it support—or hinder—human decision-making, audits, claim automation, etc…?
Just showing a model is “working” isn’t enough. We now measure when and how it adds value, track error rates and latency, improve our understanding of real world limitations and conditions, and analyze friction or efficiency gains for frontline workflows. Those lessons—especially around how to collect meaningful ground truth and tie it to system-level outcomes—directly informed our LLM evaluation strategy.
From Pixels to Prompts: Expanding M&E for LLMs
When we built Aimee, our AI companion for adolescent girls and young women in South Africa, we applied the same logic—but the tools needed to evolve.
LLMs are powerful but unpredictable. To make them safe and effective in high-stakes health contexts, we developed an M&E framework that includes:
1.Automated evaluation on benchmarks
Before deployment, we test LLMs against representative, locally-informed datasets—questions and answers (informed by healthcare professionals) from real conversations about HIV prevention, mental health, GBV, and more. This helps us select the best language model for each task—from conversation to summarization to structured data extraction .
For example, when testing responses to "If my partner has HIV, can they also use PrEP?", we saw that some models, like ChatGPT-4o Mini, gave potentially harmful or incomplete answers, while others like Claude or GPT-4 provided safer and more appropriate responses.
2. Real-time monitoring
After launch, every conversation goes through automated review. Metrics include (not a complete list):
Clinical appropriateness (correctness, completeness, harmful misinformation)
Empathy and tone
Stigma
Latency and token usage
Conciseness
If an LLM drifts—say, it starts scoring lower on stigma-sensitivity—we’re alerted immediately and re-run evaluations to select a better-performing model or fine-tune our context engine.

An example query from Aimee flagged by automated monitoring as low empathy, human labelers did not agree
This framework is not theoretical. It is actively running in our live program in South Africa where adolescent girls and young women can have conversations with Aimee - an AI companion designed to support HIV self-care, which has now processed approximately 50,000 user queries. That volume of real-world interaction gives us the ability to detect performance drifts quickly and respond with agility.
We discovered in our live program, for instance, that the automated framework sometimes under-rated empathy when the AI was collecting critical information. Community labelers with lived experience did not see this as a lack of empathy but as concern and what was needed to provide appropriate care. So we are working on retraining our empathy metric to better reflect that information collection is oftentimes a good thing, and required to provide accurate advice.
Sampled human review
Roughly 1–5% random sampling of interactions (and 100% of any interactions flagged as containing potentially harmful information from users or the LLM) are reviewed by trained clinicians (for accuracy metrics) and individuals with lived experience (for relatability metrics). Their feedback is used to tune our automated metrics—e.g., We saw variation in clinician vs. AI judgment of what counted as clinical relevance. For example, gender-based violence and mental health content was initially flagged as "non-clinical" by the automated framework but was understood as having clinical relevance by the human clinician. This is informing how we are tuning the metric in response to expert feedback.
Additionally, we learned that human evaluators were sometimes more biased than the machine—especially when trying to treat empathy and correctness independently. We addressed this by updating our labeler training, reinforcing the need to assess empathy and correctness as distinct but equally critical qualities.
The Power of Pairing: What Hybrid M&E Enables
This dual system isn’t just about catching problems—it’s about building confidence in AI systems, from users to implementers to Ministries of Health.
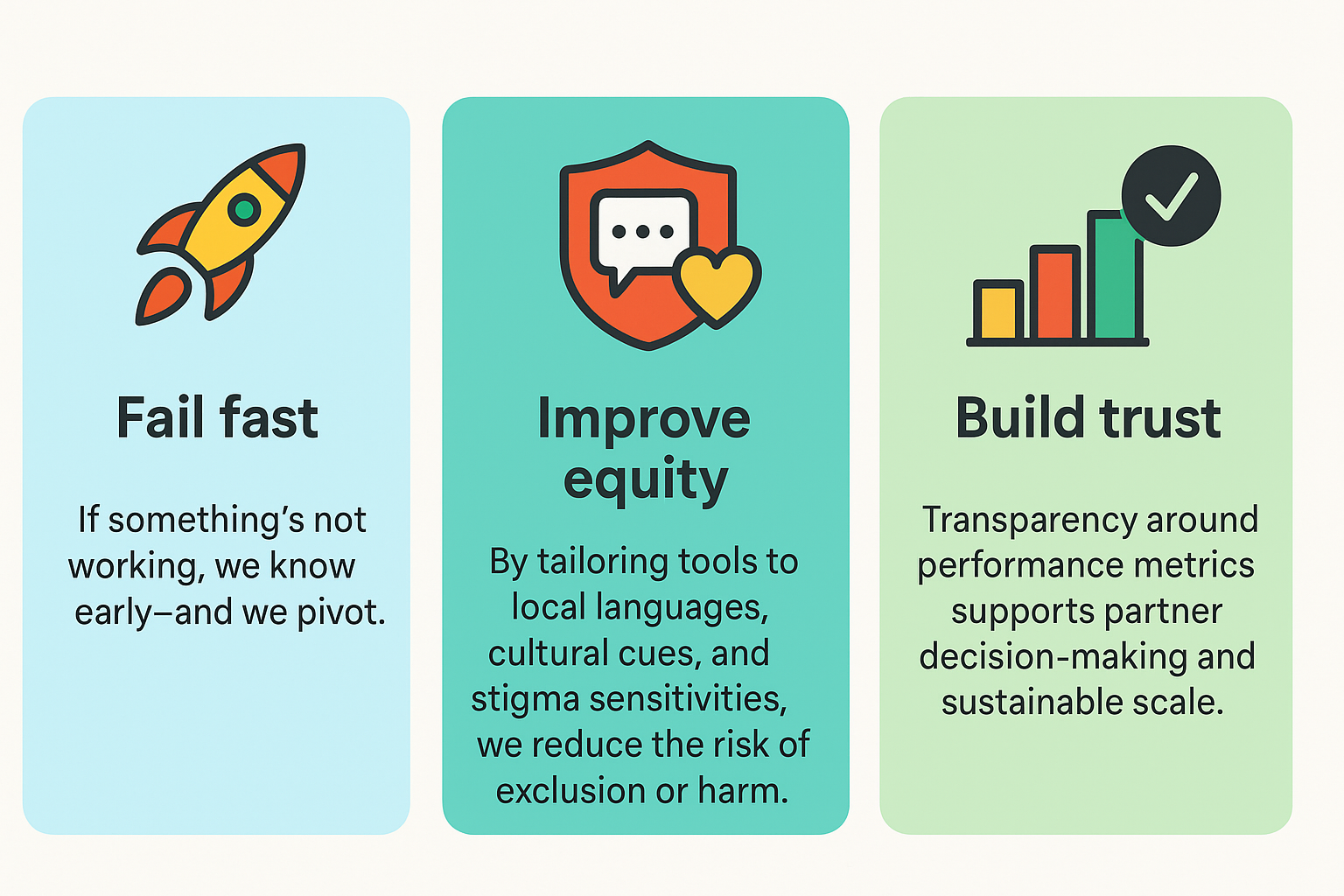
Image created with ChatGPT4o
It enables us to:
Fail fast: If something’s not working, we know early—and we pivot.
Improve equity: By tailoring tools to local languages, cultural cues, and stigma sensitivities, we reduce the risk of exclusion or harm. Equity isn’t just about language or access. It means tailoring, privacy, and responsiveness — especially when stakes are high.
This is something we have to assemble intentionally, not something that just happens with AI. And if we’re not monitoring, we won’t know when the AI gets it wrong — and we risk reinforcing the very inequities we’re trying to solve.
Build trust: Transparency around performance metrics supports partner decision-making and sustainable scale.
And critically, it allows us to keep pace with a fast-evolving ecosystem of LLMs—always choosing the right tool for the task at hand, not just the flashiest one.
Looking Ahead
This hybrid M&E framework is the backbone of our work today—but it’s also the foundation for what’s coming next.
In our next blog, we’ll introduce the Foundation Foundry: a no-code platform that lets local innovators build, customize, and monitor their own AI tools—backed by the same rigorous evaluation infrastructure we use in-house.
Because safe, equitable AI shouldn’t be reserved for the few. It should be something we all can build.